Musical instrument recognition continues to be a challenging Music Information Retrieval (MIR) problem, especially for songs with multiple instruments. This has been an active area of research for the past decade or so and while the problem is generally considered solved for individual note or solo instrument classification, the occlusion or super-position of instruments and large timbral variation within an instrument class makes the task more difficult in music tracks with multiple instruments.
In addition to these acoustic challenges, data challenges also add to the difficulty of the task. Most methods for instrument classification are data-driven, i.e., they infer or ‘learn’ patterns from labeled training data. This adds a dependence on obtaining a reliable and reasonably large training dataset for instrument classification.
Data Challenges in Instrument Classification
In previous work, we discussed briefly how there was a data problem in the task of musical instrument recognition or classification in the multi-instrument/multi-timbral setting. We utilized strongly labeled multi-track datasets to overcome some of the challenges. This enabled us to train deep CNN-based architectures with short strongly labeled audio snippets to predict fine-grained instrument activity with a time resolution of 1 second.
In retrospect we can claim that, although instrument activity detection remains the ultimate goal, current datasets are both too small in scale and terribly imbalanced in terms of both genre and instruments as shown in this figure.
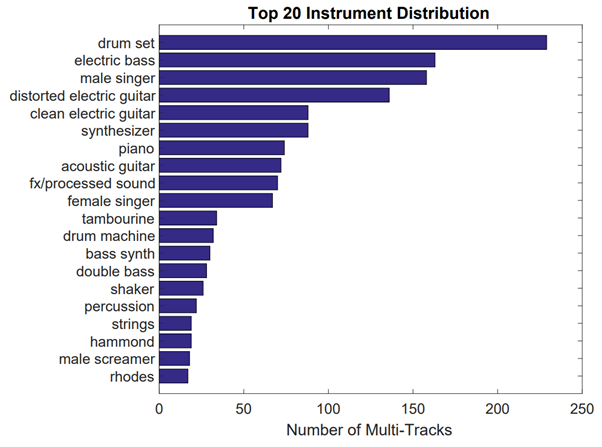
The OpenMIC dataset released in 2018 addresses some of these challenges by curating a larger-scale, somewhat genre-balanced set of music with 20 instrument labels and crowdsourced annotations for both positive (presence) and negative (absence) classes. The catch is that the audio clips here are 10 seconds long and the labels are assigned to the entire clip, i.e., fine-grained instrument activity annotations are missing. Such a dataset is what we call ‘weakly labeled.’
Previous approaches for instrument recognition are not designed to handle weakly labeled long clips of audio. Most of them are trained to detect instrument activity at short time-scales, i.e., the frame level up to 3 seconds. The same task with weakly labeled audio is tricky since instruments that are labeled as present may be present only instantaneously and could be left undetected by models that average over time.
In our proposed method, we utilize an attention mechanism and multiple-instance learning (MIL) framework to address the challenge of weakly labeled instrument recognition. The MIL framework has been explored in sound event detection literature as a means to weakly labeled audio event classification, so we decided to apply the technique to instrument recognition as well.
Method Overview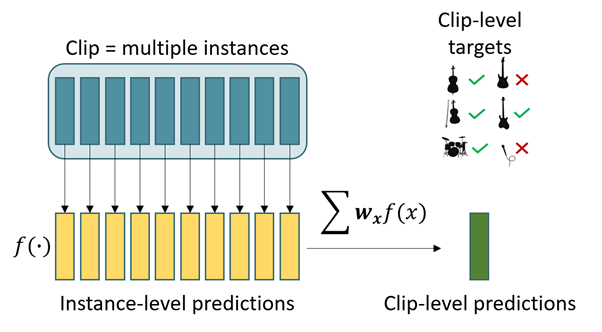
In MIL, each data point is represented as a bag of multiple instances. In our case, each bag is a 10 second clip from the OpenMIC dataset. We divide the clip into 10 instances, each of 1 second. Each instance is represented by a 128-dimensional feature vector extracted using a pre-trained VGGish model. Thus, a clip input is 10×128 dimensional. As per the MIL framework, each bag is associated with a label. This implies that at least one instance in the bag is associated with the same label, we just don’t know which one. To learn in the MIL setting, algorithms perform a weighted sum of instance-level predictions to obtain the bag-level predictions. These predictions can be compared with the bag-level labels to train the algorithm. In our paper, we utilize learned attention weights for the aggregation of instance-level predictions.
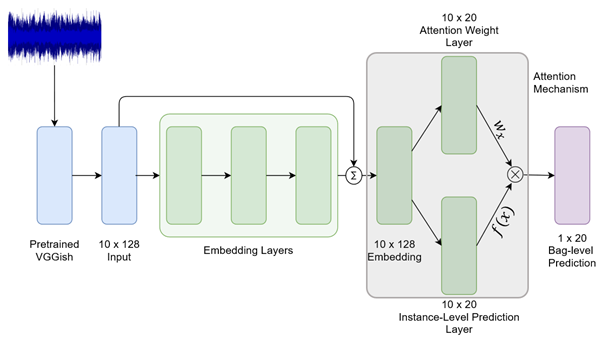
Looking at the model architecture in the figure above, the model estimates instance-level predictions and instance-level attention weights. We estimate one weight per instance per instrument label. The weights are normalized across instances to sum to one, adding an interpretation of relative contribution each instance prediction has on the final clip-level prediction for a particular instrument.
Results
We compared this model architecture with mean pooling, recurrent neural networks, fully connected networks and binary random forests and found our attention-based model to outperform all the other methods, especially in terms of the recall. We also tried to visualize the attention weights and see if the model was focusing on relevant parts of the audio as it was supposed to.
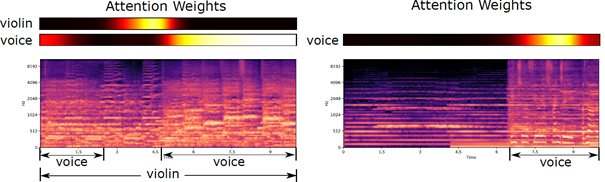
As you can see in the above image, while this model is not very adept at localizing the instruments (in the first example, violin is actually in all instances, but model applies high weights only to a couple of instances), it does a good job at seeking out easy to classify instances and focuses weights on those.
Conclusion
In conclusion, we discuss the merits of weakly labeled audio datasets in terms of ease of annotation and scalability. In our opinion, it is important to develop methods capable of handling weakly labeled data due to the ease of annotation and therefore scalability of such datasets. To that end, we introduce the MIL framework and discuss the attention mechanism in brief. Finally, we show a visualization of how the attention weights provide some degree of interpretability to the model. Even though the model is not perfectly localizing the instruments, it learns to focus on relevant instances for final prediction.
The detailed paper can be found here.