by Jiawen Huang and Yun-Ning Hung
Learning to play a musical instrument usually requires continuing feedback from a trained professional to guide the learning process. Although reduced face-time with a teacher might make instrument learning more accessible, it also slow the learning process down. An automatic music performance assessment system, however, might fill this gap by providing instant and objective feedback to the student during practice sessions.

Some of the previous research extract features from both the performance audio and the score. With the rise of deep learning, neural networks replaced traditional feature extraction. However, the vast majority of previous studies focus on the audio information and ignore the score information. This, however, discards a significant amount of arguably important side information that could be utilized for assessing the student performance.
In this work, we explore different methods to incorporate musical score information into deep-learning models for music performance assessment. Our hypothesis is that including this information will lead to improved performance of deep networks for this task. More specifically, we present three architectures which combine score and audio inputs to make a score-informed assessment of a music performance. We refer to these three architectures as Score-Informed Network, Joint Embedding Network and Distance Matrix Network. The input of all three networks is based on the extracted fundamental frequency contour converted to pitches.
Score-Informed Network (SIConvNet)

The input representation for SIConvNet is constructed by stacking an aligned pitch contour and score pair to create a N × 2 matrix. The matrix is then fed into 4-layer 1-D convolutional layers followed by a linear layer, as shown in Figure 2.
Joint Embedding Network (JointEmbedNet)
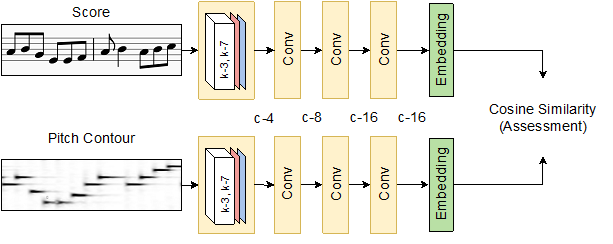
The second approach is based on the assumption that performances are rated based on perceived distance between the performance and the underlying score being performed. The individual N × 1 sequences are fed separately into two encoders to project the score and the pitch contour to a joint latent space. Then, we use the cosine similarity cos(Escore, Eperformance) between the two embeddings to obtain the predicted assessment rating.
Distance Matrix Network (DistMatNet)

The final approach assumes that given the information from both the pitch contour and the score, the task of performance assessment can be interpreted as finding a performance distance between them. As a result, we use a distance matrix between the pitch contour and the score as the input to the network to learn the pitch difference. A deep residual architecture with two linear layers is used to perform assessment score prediction.
Experiments
The dataset we use is a subset of a large dataset of middle school and high school student performances recorded for the Florida All State Auditions. The recordings contain auditions spanning 6 years (from 2013 to 2018), featuring several monophonic pitched and percussion instruments, and include several exercises. In this experiment, we limit ourselves to the technical etude for middle school and symphonic band auditions. We choose Alto Saxophone, Bb Clarinet, and Flute performances due to these being the most populated instrument classes. Each performance is rated on a point-based scale by one expert along 4 criteria defined by the Florida Bandmasters’ Association (FBA): (i) musicality, (ii) note accuracy and (iii) rhythmic accuracy. As a result, all the models mentioned above are trained to predict the regression ratings (which are normalized between 0 and 1) given by the experts.
Results
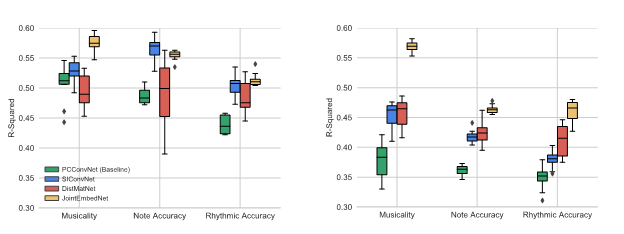
We compared our methods with the baseline (score-independent) model in our previous work. The results show that:
- Although all score-informed models generally outperform the baseline, the difference between baseline and score-informed models is smaller for the middle school. This implies that a score reference becomes more impactful with increasing proficiency level.
- All systems perform better (higher R2 value) on the middle school recordings than on the symphonic band recordings. Possible explanation is that symphonic band scores are usually more complicated and longer. Furthermore, symphonic band auditions might exhibit greater skill level than middle school performers, which could complicate modeling the differences.
- While the two models SIConvNet and JointEmbedNet both use the same input features, JointEmbedNet outperforms SIConvNet in most of the experiments. We can assume that JointEmbedNet is able to explicitly model the differences between the input pitch contour and score.
- While both DistMatNet and JointEmbedNet utilize the similarity between the score and pitch contour, JointEmbedNet typically performs better across categories and bands.
Conclusion
This work presents three novel neural network-based methods that combine score information with a pitch representation of an audio recording to assess a music performance. The results show a considerable improvement over the baseline model. One shortcoming of the investigated models is that they are agnostic to timbre and dynamics information, which might be critical factors in performance assessment. We leave this area for future research.