by Sunshiyu Wang
FoleySet is a new publicly available dataset of 10,000 human-annotated Foley audio clips designed to address a key gap in Foley research: the lack of structured, fine-grained, human-annotated Foley sound datasets. As evoloving machine learning approaches create new opportunities for Foley sound classification, retrieval, synchronization, and generation, high-quality datasets are essential for developing and evaluating reliable models. FoleySet provides this foundation through a two-level taxonomy containing 9 major categories and 73 sub-categories, covering sounds such as footsteps, clothing movement, human-produced sounds, liquid sounds, metal interactions, clicks, break/drop events, material interactions, and open/close mechanisms.
Because Foley does not have a universally unambiguous definition, we define it as sounds arising from human-related actions, including human-produced sounds and human interactions with materials, objects, and surfaces. Based on this definition, we developed a Foley-specific taxonomy by reviewing prior research, Foley practice, and commercial Foley sound libraries. Common Foley-related keywords were extracted, normalized, and manually refined into the final two-level taxonomy. Using this taxonomy, FoleySet was built through a multi-step pipeline: candidate clips were collected from Creative Commons Zero-licensed Freesound recordings, manually screened, standardized through audio processing, and annotated with major-category, sub-category, and one-shot/multi-shot labels. The final dataset includes training, validation, and test splits, along with metadata such as Freesound tags, descriptions, source IDs, uploader information, and URLs.
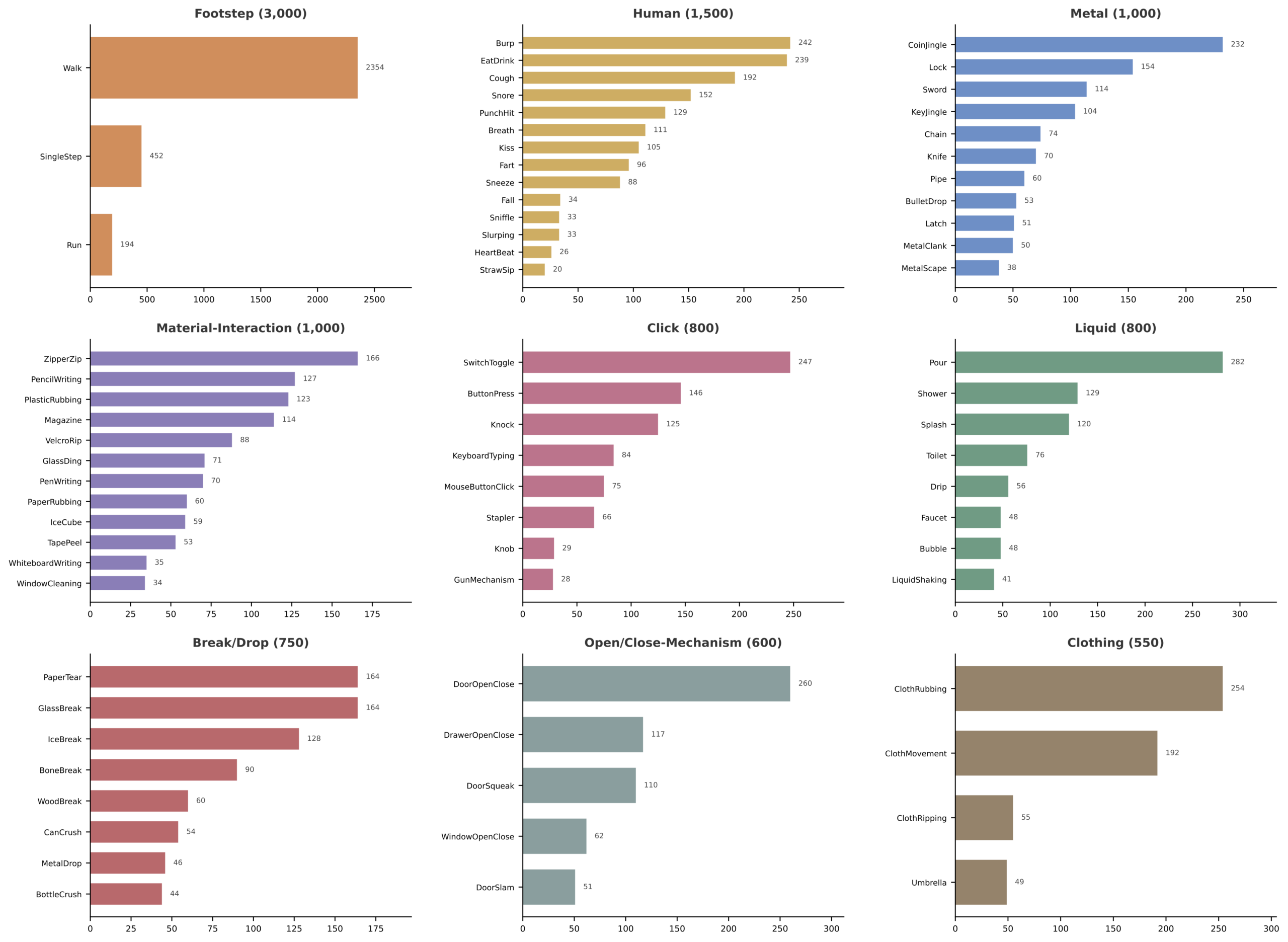
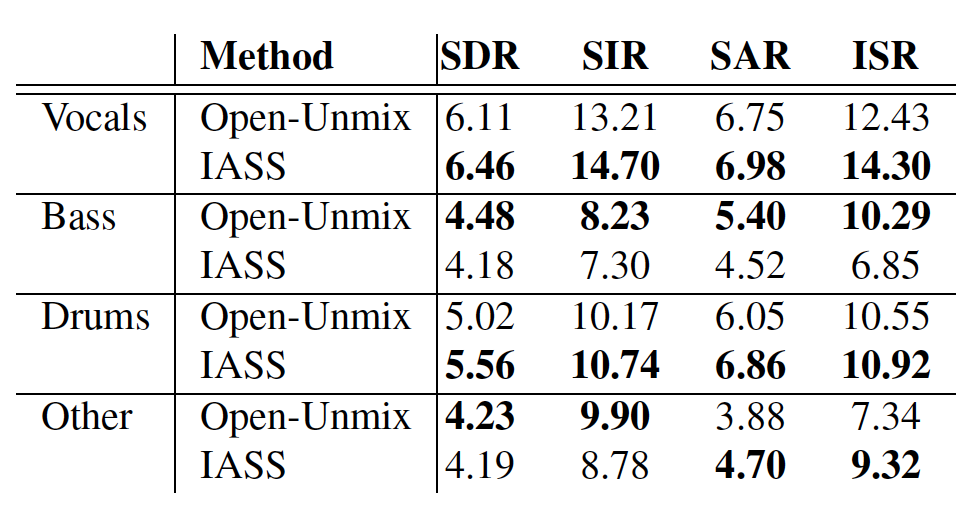
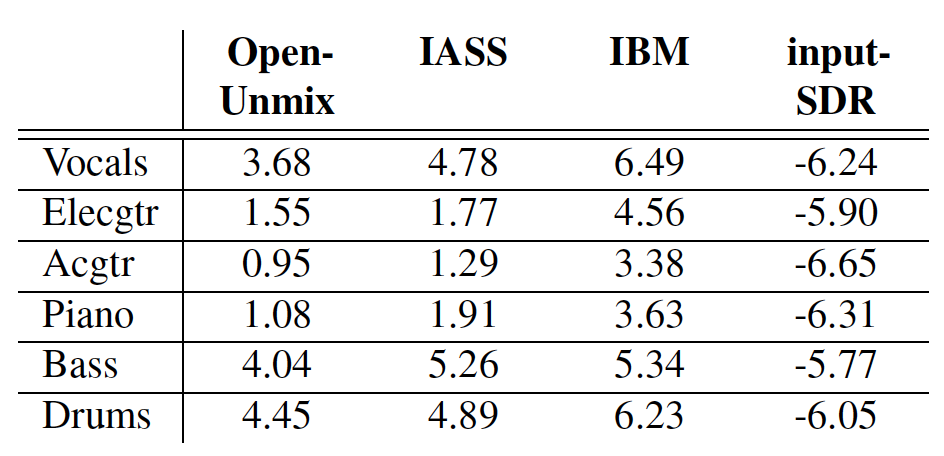
We also provide baseline classification results using a PaSST-based audio embedding model. The model performs well on the 9-way major-category classification task, while the more fine-grained 73-way sub-category task remains challenging, especially for acoustically similar or underrepresented Foley sounds. Overall, FoleySet provides a practical dataset and Foley-specific taxonomy for developing models that retrieve, classify, and generate detailed sounds of human action and material interaction, with the goal of supporting future Foley research and contributing to broader audiovisual production workflows.
Dataset link: FoleySet
Paper link: Paper