by Benjamin Genchel
The advent of modern deep learning has rapidly propelled progress and attracted interest in symbolic music generation, a research topic that encompasses methods of generating music in the form of sequences of discrete symbols. While a variety of techniques have been applied to tasks in this domain, the majority of approaches treat music as a temporal sequence of events and rely on Recurrent Neural Networks (RNNs), specifically the gated variants Long Short-Term Memory (LSTM) and Gated Recurrent Units (GRU), to model this sequence. These approaches generally attempt only to learn to predict the next note event(s) in a series given previous note event(s). While results from these types of models have been promising, they train on hard mode relative to human musicians, who rely on explicit, discretely classed information such as harmony, feel (e.g. swing, straight), phrasing, meter, and beat to organize and contextualize while learning.
Our study aims to investigate how deep models, specifically gated RNNs, learn when provided with explicit musical information, and further, how particular types of explicit information affect the learning process. We describe the results of a case study in which we compared the effects on musical output of conditioning an RNN-based model like those mentioned above with various combinations of a select group of musical features.
Specifically, we separate musical sequences into sequences of discrete pitch and duration values, and model each sequence independently with its own LSTM-RNN. We refer to these as Pitch-RNN and Duration-RNN respectively. Then we train a pair of these models using combinations of the following:
- Inter Conditioning: the pitch generation network is provided with the corresponding duration sequence as input and vice versa.
- Chord Conditioning: both the pitch and duration networks are provided with a representation of the current chord for each input timestep.
- Next Chord Conditioning: both the pitch and duration networks are provided with a representation of the chord following the current chord for each input timestep.
- Bar Position Conditioning: both the pitch and duration networks are provided with a discrete value representing the position within a surrounding bar of the current input token.
For a more clear picture of what we’re doing, check out this architecture diagram!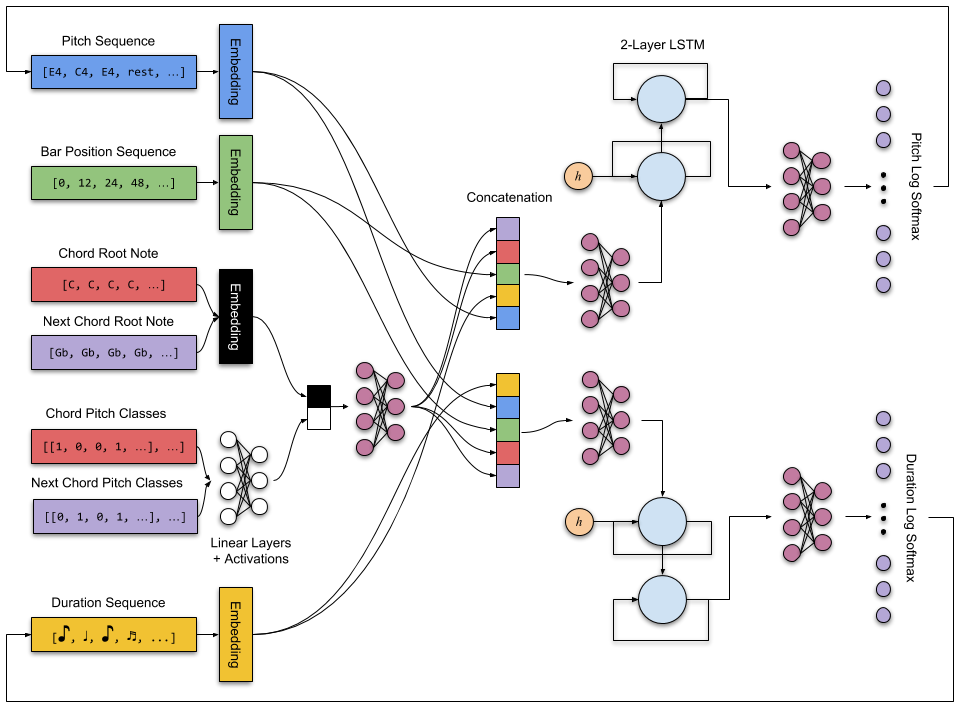
Data
We trained our models using two datasets (Bebop Jazz and Folk) of lead sheets (data extracted from musicXML files), as lead sheets provide a simplified description of a song that is already segmented into explicit components.
Evaluation
Evaluating generative music is a challenging and precarious task. In lieu of an absolute metric for quality, we characterize the outputs of each trained model using a set of statistical methods:
- Validation NLL — The final loss achieved by a model on the validation set.
- BLEU Score — a metric originally designed for machine translation, but deployed fairly commonly for judging sequence generation in general, BLEU score computes a geometric mean of the counts of matching N-grams (specifically 1, 2, 3, and 4-grams) between a set of ground truth data and a data set generated by a model. A BLEU score can be between 0 and 1, with 0 being nothing in common and 1 being everything in common (exactly matching).
- MGEval — the MGEval toolbox, created by our own Li-Chia “Richard” Yang and Alexander Lerch, and described in an earlier blog post on this page, calculates KL-divergence and overlap scores between distributions of a number of music specific statistical features calculated for a set of ground truth data and generated data. These scores give an idea of how much generated data differs from the ground truth, and further provides insight into how they differ in musical terms.
Results
Validation NLL
The general trend observed was, perhaps unsurprisingly, that the more conditioning information used, the lower the final loss. Additionally, models trained with more conditioning learned faster than trained with less.
BLEU Score
Pitch models generally achieved a higher BLEU score with added conditioning factors, while Duration networks demonstrated the opposite trend — lower scores with added conditioning factors. The highest scoring pitch models had both chord and next chord conditioning, though models trained on the Bebop dataset seemed to generally perform better with current chord conditioning than next-chord conditioning, while models trained on the Folk dataset performed better with next-chord conditioning. The highest scoring duration models for both datasets had no-conditioning at all, and the next highest scoring models had only one conditioning factor.
While a BLEU score close to 1 might be ideal for machine translation, for artistic tasks like music generation where there is no right answer, a score that high hints at overfitting, and thus a lack of ability to generalize what it has learned and create novel melodies in unfamiliar contexts. While pitch models scored between .1 and .3, duration models scored from .5 to .9; that duration models with less conditioning scored higher than those with more may actually indicate that models with more conditioning generalized better, as their scores were closer to .5
MGEval
MGEval produces a lot of numbers — In our case, 66 for a single model (6 scores each for 11 MGEval metrics we used). We aggregated these results in a way that gives each individual conditioning factor a probability indicating its likelihood of contributing to higher performance. We split our 11 metrics into two categories, pitch-based, and duration-based, and performed this aggregation for each set:

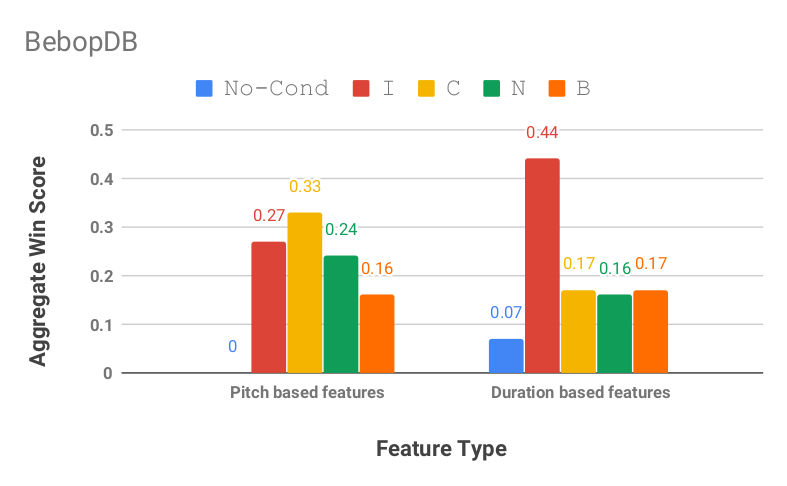
In general, we observed that scores on MGEval metrics improve with the addition of conditioning features, but with these aggregation scores, we were able to ascertain (at a high level) which types of conditioning were affecting what. For both datasets, inter and chord conditioning had strong effects on pitch based features, with bar position conditioning a close third. However, for duration based features, it’s harder to determine. We can see here that for models trained on the Folk set, it’s a bit of a grab bag, but for models trained on the Bebop set, chord and bar position clearly contribute the most to success. This is perhaps due to the much simpler, and more repetitive rhythmic patterns found in Folk music as compared to Bebop Jazz music.
Conclusions
Solid takeaways from this study are that conditioning with chords is important not just for pitch prediction, but for duration prediction as well, though the usefulness of conditioning with the next chord vs. the current chord was harder to determine. More generally, we were also able to gain insight into the relative usefulness of our chosen conditioning set for pitch and rhythm based features. Additionally, we saw that the usefulness of particular features can also be genre dependent. Further investigation, along with a subjective evaluation via listening test is certainly worthwhile.
Check out our paper, the associated website, or the codebase for more details, audio samples, data and other information!