by Li-Chia Richard Yang
Generative modeling among creative systems has research interest in a wide variety of tasks. Just as deep learning has reshaped the whole field of artificial intelligence, it has reinvented generative modeling in recent years, e.g., in music or painting. Regardless, however, of the research interest in generative systems, the assessment and evaluation of such systems has proven challenging.
In recent research on music generation, various data-driven models have shown promising results. As a quick example, here are two generated samples from two distinct systems:
Now, how can we analyze and compare the behavior of these models?
As the ultimate judge of creative output is the human (listener or viewer), subjective evaluation is generally preferable in generative modeling. However, the general drawbacks of subjective evaluation can be summarized as various issues related to the required amount of resources and to the experiment design. Furthermore, objective evaluation has the advantage of providing a systematic, repeatable measurement across a significant amount of generated samples.
The proposed evaluation strategy

The proposed method does not aim at assessing musical pieces in the context of human-level creativity nor does it attempt to model the aesthetic perception of music.
It rather applies the concept of multi-criteria evaluation in order to provide metrics that assess basic technical properties of the generated music and help researchers identify issues and specific characteristics of both model and dataset. In a first step, we define two collections of samples as our datasets (in case of objective evaluation, one dataset contains the generated samples, the other contains samples from the training dataset). Then, we extract a set of features based on musical domain-knowledge for two main targets of the proposed evaluation strategy:
Absolute MeasurEments
Absolute measurements give insights into properties and characteristics of a generated or collected set of data.
During the model design phase of a generative system, it can be of interest to investigate absolute metrics from the output of different system iterations or of datasets as opposed to a relative evaluation. A typical example is the comparison of the generated results from two generative systems: although the model properties cannot be determined precisely for a data-driven approach, the observation of the generated samples can justify or invalidate a system design.
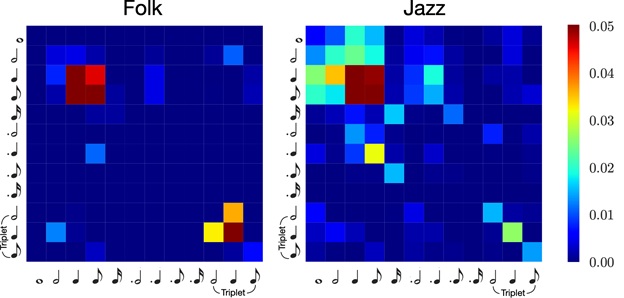
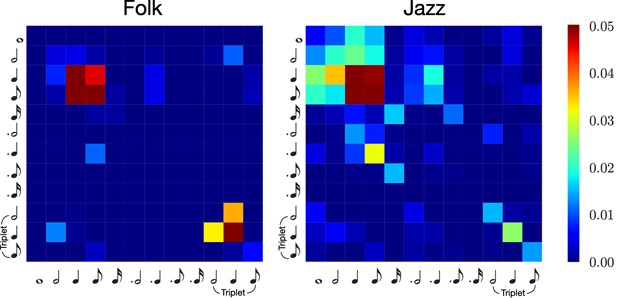
For instance, an absolute measurement can be a statistic analysis of note length transition histogram of each sample of a given dataset. In the following figure, we can easily observe the difference of such this feature among datasets from two different genres.
Relative Measurements
In order to enable the comparison of different sets of data, the relative measure generalizes the result among features with various dimensions.
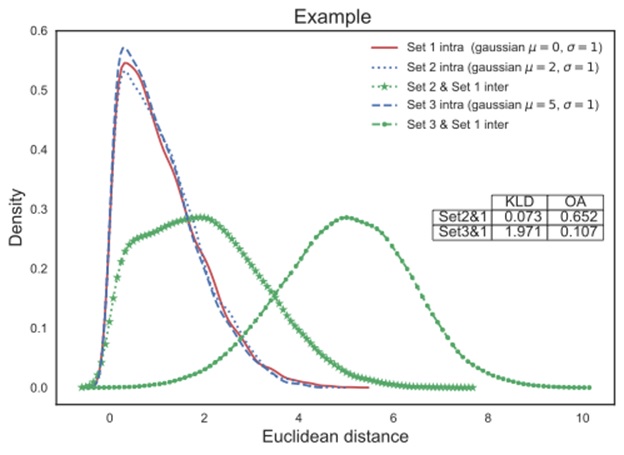
We first perform pairwise exhaustive cross-validation for each feature and smooth the histogram results into probability density functions (PDFs) for a more generalizable representation. If the cross-validation is computed within one set of data, we will refer to it as intra-set distances. If each sample of one set is compared with all samples of the other set, we call it the inter-set distances.
Finally, we measure the similarity between these distributions for the application of evaluating music generative systems, and compute two metrics between the target dataset’s intra-set PDF and the inter-set PDF: the Kullback-Leibler Divergence (KLD) and overlapped area (OA) of two PDFs.
Take the following visualized figure as an example: assume set1 is the training data, while set2 and set3 correspond to generated results from two systems. The analysis can provide a quick observation It can be easily observed that the system that generates generated set2 produces results more in line has a closer behavior in such feature with the training data (in the context of this feature).
Find out more
Check out our paper for detailed use-case demonstration and the released toolbox for further application.