We had two great days with Masataka Goto (AIST, Japan) visiting the Georgia Tech Center for Music Technology. Thanks Masataka for great presentations, discussions, and ideas!

We had two great days with Masataka Goto (AIST, Japan) visiting the Georgia Tech Center for Music Technology. Thanks Masataka for great presentations, discussions, and ideas!
by Chih-Wei Wu
Building a computer system that “listens” and “understands” music is the goal of many researchers working in the field of Music Information Retrieval (MIR). To achieve this objective, identifying effective ways of translating human domain knowledge into computer language is the key. Machine learning (ML) promises to provide methods to fulfill this goal. In short, ML algorithms are capable of making decisions (or predictions) in a way that is similar to human experts; this is achievable by browsing and observing patterns within so called “training data.” When large amounts of data are available (e.g., images and text), modern ML systems can perform comparably or even outperform human experts in tasks such as object recognition in images.
Similarly, to train a successful ML model for MIR tasks, (openly available) data also plays an essential role. Useful training data usually includes both the raw data (e.g., audio files, video files) and annotations that describe the answer for a certain task (such as the music genre, the tempo of the music). With a reasonable amount of data and correct ground truth labels, the ML models may build a function that maps the raw data to their corresponding answers.
One of the first questions new researchers ask is: “How much data is needed to build a good model?” The short answer to the first question is the more the better. This answer may be a little unsatisfying, but it is often true for ML algorithms (especially the increasingly popular deep neural networks!). The human annotation of data, however, is labor-intensive and does not scale well. This situation gets worse when the target task requires highly skilled annotators and crowdsourcing is not an option. Automatic Drum Transcription (ADT), a process that extracts the drum events from the audio signals, is a good example of such skill demanding task. To date, most of the existing ADT datasets are either too small or too simple (synthetic).
To find a potential solution for this problem, we try to explore the possibility of having ML systems learn from the data without labels (as shown in Fig. 1).
Unlabeled data has the following advantages: 1) it is easily available compared to labeled data, 2) it is diverse, and 3) it is realistic.
We explore a fascinating way of using unlabeled data referred to as the “student-teacher” learning paradigm. In a way, it uses “machines to teach machines.” As researchers have been working on systems for drum transcription before, these existing systems can be utilized as teachers. Multiple teachers “transfer” their knowledge to the student and the unlabeled data is used as the medium to carry the knowledge of the teachers. The teachers make their predictions on the unlabeled data and the student will try to mimic the teachers’ predictions and become better and better at certain task. Of course, the teachers might be wrong, but the assumption is that multiple teachers and a large amount of data will compensate for this.
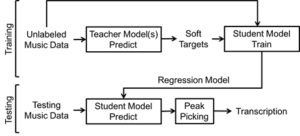
Figure 2 shows the presented system consisting of a training phase and a testing phase. During the training phase, all teacher models will be used to generate their predictions on the unlabeled data. These predictions will become “soft targets” or pseudo ground truth. Next, the student model is trained on the same unlabeled data with the soft targets. In the testing phase, the trained student model will be tested against an existing labeled dataset for evaluation.
The exciting (preliminary) result of this research is that the student model is actually able to outperform the teachers! Through our evaluation, we show that it is possible to get a student model that outperforms the teacher models on certain drum instruments for ADT task. This finding is encouraging and shows the potential benefits we can get from working with unlabeled data.
For more information, please refer to our full paper. The unlabeled dataset can be found on github.
by Chih-Wei Wu
Data availability is the key to the success of many machine learning based Music Information Retrieval (MIR) systems. While there are different potential solutions to deal with insufficient data (for instance., semi-supervised learning, data augmentation, unsupervised learning, self-taught learning), the most direct way of tackling this problem is to create more annotated datasets.
Automatic Drum Transcription (ADT) is, similar to most of the MIR tasks, in need of more realistic and diverse datasets. However, the creation process of such datasets is usually difficult for the following reasons: 1) the synchronization between the drum strokes the onset times has to be exact. In previous work, this was done by installing triggers on the drum sets. However, the installation and the recording process also limits the size of the dataset. Another work around solution is to synthesize drum tracks with user defined onset time and drum samples; this will result in drum tracks with perfect ground truth, but the resulting music might be unrealistic and unrepresentative of the real-world music. 2) the variety of the drum sounds has to be high enough to cover a wide range from electronic to acoustic drum sounds. Most of the previous work only uses a small subset of drum sounds (e.g., certain drum machines or a few drum kits), which is not ideal in this regard. 3) the playing techniques can be hard to differentiate, especially on instruments such as snare drum. A majority of existing datasets only contain the annotations of the basic strikes for simplicity.
We try to address the above mentioned difficulties by introducing a new ADT dataset with a semi-automatic creation process.
The goal of this project is to create a new dataset with minimum effort from the human annotators. In order to achieve this goal, a robust onset detection algorithm to locate the drum events is important. To ensure the robustness of the onset detector, we want the input signal to be as clean as possible. However, we also want to have a signal to be as realistic as possible (i.e., polyphonic mixtures of both melodic and percussive instruments). With these considerations in mind, we decided to avoid collecting a new dataset from scratch but rather work on the existing dataset with desirable properties.
As a result, the MusicDelta subset in the MedleyDB dataset is chosen for its:
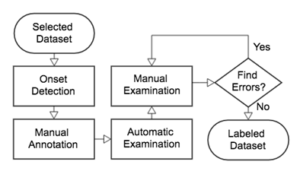
The processing flow of the creation of MDB Drum is shown in Fig. 1. First, the songs in the selected dataset are processed with an onset detector. This provides a consistent estimation of the onset locations. Next, the onsets are labeled with their corresponding instrument names (i.e., Hi-hat, Snare Drum, Kick Drum). This step inevitably requires manual annotation from the human experts. Following the manual annotation, a set of automatic checks were implemented to examine the annotations for common errors (e.g., typos, duplicates). Finally, the human experts went through an iterative process of cross-checking their annotations prior to the release of the dataset.
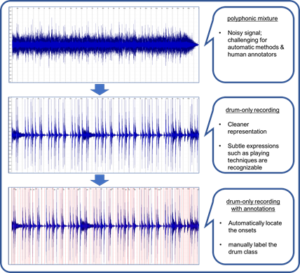
An dataset example is shown in Fig. 2. The original polyphonic mixture (top) appears noisy, and it is difficult to locate the drum events through both listening and visual inspection. The drum-only recording (middle), however, has sharp attacks and short decays in the waveform, providing a cleaner representation for the onset detector. Finally, the detected onsets (bottom), as marked in red, are relatively accurate, which greatly simplifies the process of manual annotation.
The resulting dataset contains 23 tracks of real-world music with a diverse distribution of music genres (e.g., rock, disco, grunge, punk, reggae, jazz, funk, latin, country, britpop, to name just a few). The average duration of the tracks is around 54s, and the number of annotated instrument classes is 6 (only major classes) or 21 (with playing techniques). The users may choose to mix the multitracks in any combination (e.g., guitar + drum, bass + drum) due to the multitrack format of the original MedleyDB dataset.
All details can be found in our short paper here.
by Amruta Vidwans
Learning a musical instrument is difficult. It needs regular practice, expert advice, and supervision. Even today, musical training is largely driven by interaction between student and a human teacher plus individual practice session at home.
Can technology improve this process and the learning experience? Can an algorithm perform an assessment of a student music performance? If yes, we are one step closer to a truly musically intelligent music tutoring system that will support students learn their instrument of choice by providing feedback on aspects like rhythmic correctness, note accuracy, etc. An automatic assessment is not only useful to students for their practice sessions but could also help band directors in the auditioning and (pre-)selection process. While there are a few commercial products for practicing instruments, the assessment in these products is usually either trivial or opaque to the user.
The realization of a musically intelligent system for music performance assessment requires knowledge from multiple disciplines such as digital signal processing, machine learning, audio content analysis, musicology, and music psychology. With recent advances in Music Information Retrieval (MIR), noticeable progress has been made in related research topics.
Despite these efforts, identifying a reliable and effective method for assessing music performances remains an unsolved problem. In our study, we explore the effectiveness of various objective descriptors by comparing three sets of features extracted from the audio recording of a music performance, (i) a baseline set with common low-level features (often used but hardly meaningful for this task), (ii) a score-independent set with designed performance features (custom-designed descriptors such as pitch deviation etc., but without knowledge of the musical score), and (iii) a score-based set with designed performance features (taking advantage of the known musical score). The goal is to identify a set of meaningful objective descriptors for the general assessment of student music performances. The data we used covers Alto Saxophone recordings of three years of student auditions (Florida state auditions) rated by experts in the assessment categories of musicality, note accuracy, rhythmic accuracy, and tone quality.
| Label: Musicality | E1 | E2 | E3 | E4 |
| Correlation (r) | 0.19 | 0.49 | 0.56 | 0.58 |
Our observations (as seen in Table 1) are that, as expected, the baseline features (E1) are not able to capture any qualitative aspects of the music performance so that the regression model mostly fails to predict the expert assessments . Another expected result is that score-based features (E3) are able represent the data generally better than score-independent features (E2) in all categories. The combination of score-independent and score-based features (E4) show some trend to improve results, but the gain remains small, hinting at redundancies between the feature sets. With values between 0.5 and 0.65 for the correlation between the prediction and the human assessments, there is still a long way to go before computers will be able to reliably assess student music performance, but the results show that an automatic assessment is possible to a certain degree.
To learn more, please see the published paper for details.
Header image used with kind permission of Rachel Maness from http://wrongguytoask.blogspot.com/2012/08/woodwinds.html