by Siddharth Gururani
The term ‘sampling’ refers to the reuse of audio snippets from pre-existing digital recordings with appropriate modifications in new compositions in a way that it fits the musical context. Influential artists that have been sampled frequently by younger artists include, for example, James Brown, Stevie Wonder, and Michael Jackson. Since sampling is an important approach in at least some music genres, there are websites dedicated to linking samples to songs such as whosampled.com. The annotation, however, is done manually by fans and
music aficionados. A system that can automatically detect sampling can help automate this process and could also be used in large scale musicological studies of artist influence across time and geographical space.
The task of automatic sample detection has not been explored in much detail. Some papers proposed methods involving a modified audio fingerprinting method and Non-negative Matrix Factorization (NMF). The block diagram below gives a broad overview of the method used in this work.
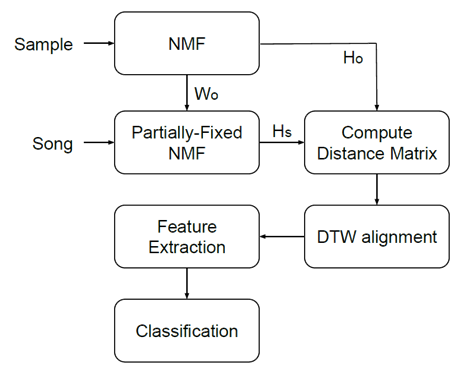
The algorithm we present also utilizes NMF and adds a post-processing step with subsequence Dynamic Time Warping (DTW) to extract features that indicate a sample/song pair. The figure below shows a distance matrix for a song in which the sample is looped 4 times in 20 seconds as indicated by the diagonal lines. We extract features from the detected paths and use them to train a random forest classifier.

A new dataset had to be created for the evaluation of the system as previous publications lack systematic evaluation. This dataset originates from whosampled.com and is now publicly available. Our evaluation results, presented in the paper, indicate that our algorithm is has reasonably high precision while suffering from low recall which may be attributed to absence of clear alignment paths in the distance matrix.
For details on the method, results and discussion, please refer to the published paper available here.