by Ashis Pati
Motivation
In the field of machine learning, it is often required to learn low-dimensional representations which capture important aspects of given high-dimensional data. Learning compact and disentangled representations (see Figure 1) from given data, where important factors of variation are clearly separated, is considered especially useful for generative modeling.
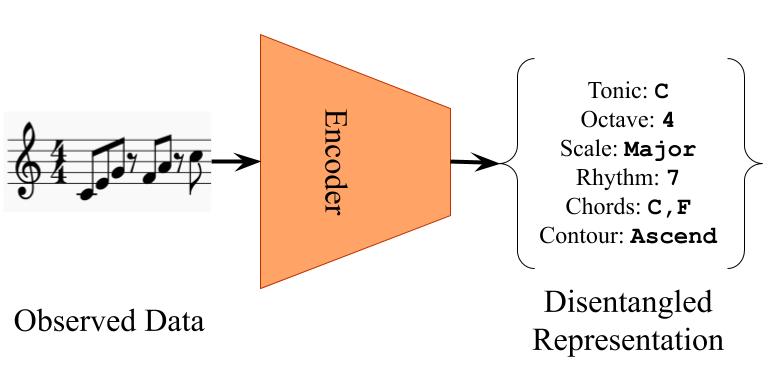
However, most of the current/previous studies on disentanglement have relied on datasets from the image/computer vision domain (such as the dSprites dataset).
We propose dMelodies, a standardized dataset for conducting disentanglement studies on symbolic music data which will allow:
- researchers working on disentanglement algorithms evaluate their method on diverse domains.
- systematic and comparable evaluation of methods meant specifically for music disentanglement.
dMelodies Dataset
To enable objective evaluation of disentanglement algorithms, one needs to either know the ground-truth values of the underlying factors of variation for each data point, or be able to synthesize the data points based on the values of these factors.
Design Principles
The following design principles were used to create the dataset:
- It should have a simple construction with homogeneous data points and intuitive factors of variation.
- The factors of variation should be independent, i.e., changing any one factor should not cause changes to other factors.
- There should be a clear one-to-one mapping between the latent factors and the individual data points.
- The factors of variation should be diverse and span different types such as discrete, ordinal, categorical and binary.
- The generated dataset should be large enough to train deep neural networks.
Dataset Construction
Based on the design principles mentioned above, dMelodies is artificially generated dataset of simple 2-bar monophonic melodies generated using 9 independent latent factors of variation where each data point represents a unique melody based on the following constraints:
- Each melody will correspond to a unique scale (major, harmonic minor, blues, etc.).
- Each melody plays the arpeggios using the standard I-IV-V-I cadence chord pattern.
- Bar 1 plays the first 2 chords (6 notes), Bar 2 plays the second 2 chords (6 notes).
- Each played note is an 8th note.
A typical example is shown below in Figure 2.

Factors of Variation
The following factors of variation are considered:
1. Tonic (Root): 12 options from C to B
2. Octave: 3 options from C4 through C6
3. Mode/Scale: 3 options (Major, Minor, Blues)
4. Rhythm Bar 1: 28 options based on where the 6 note onsets are located in the first bar.
5. Rhythm Bar 2: 28 options based on where the 6 note onsets are located in the second bar.
6. Arpeggiation Direction Chord 1: 2 options (up/down) based on how the arpeggio is played
7. Arpeggiation Direction Chord 2: 2 options (up/down)
8. Arpeggiation Direction Chord 3: 2 options (up/down)
9. Arpeggiation Direction Chord 4: 2 options (up/down)
Consequently, the total number of data-points are 1,354,752.
Benchmarking Experiments
We conducted benchmarking experiments using 3 popular unsupervised algorithms (beta-VAE, Factor-VAE, and Annealed-VAE) on the dMelodies dataset and compared the result with those obtained using the dSprites dataset. Overall, we found that while disentanglement performance across different domains is comparable (see Figure 3), maintaining good reconstruction accuracy (see Figure 4) was particularly hard for dMelodies.
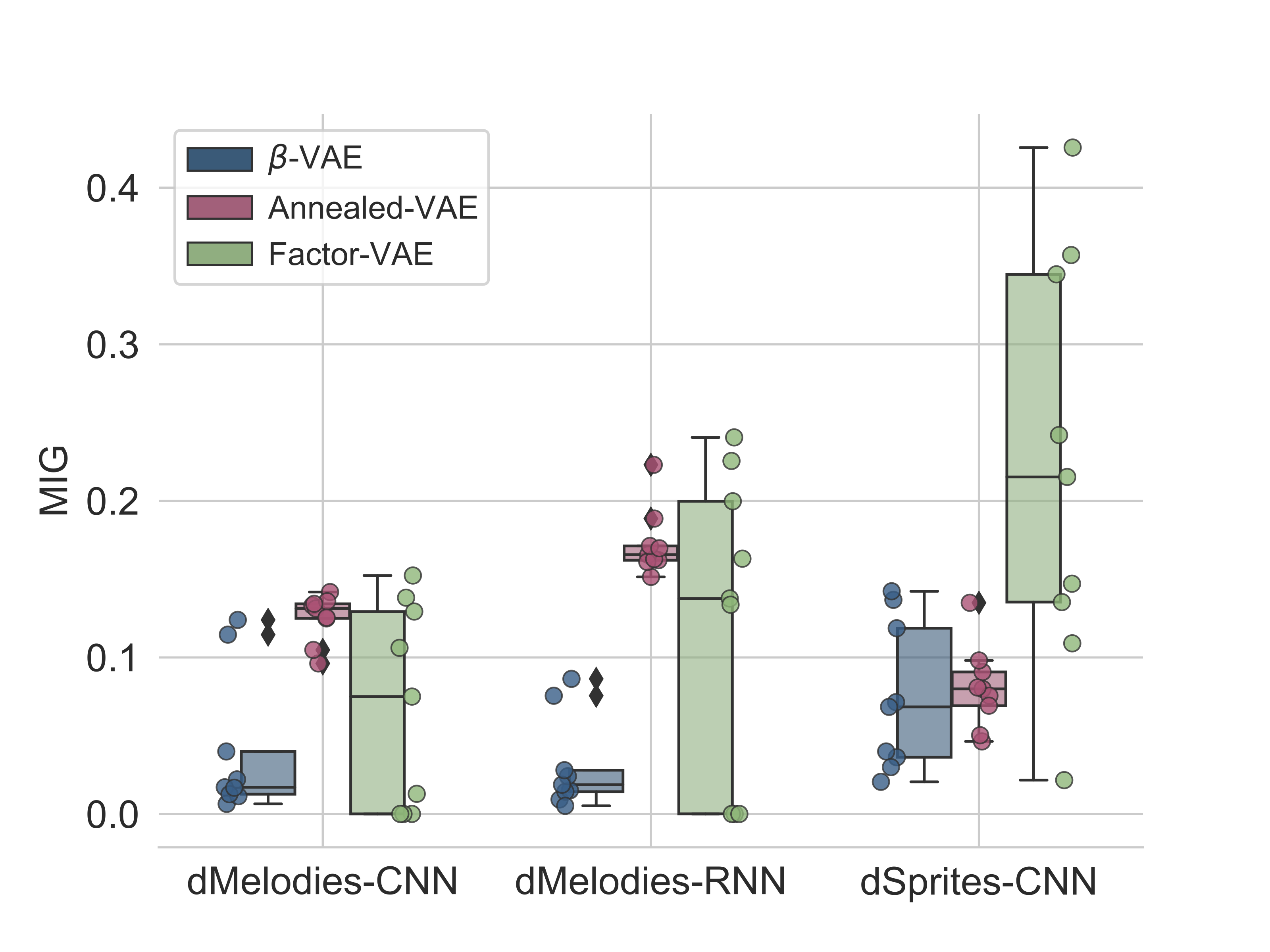
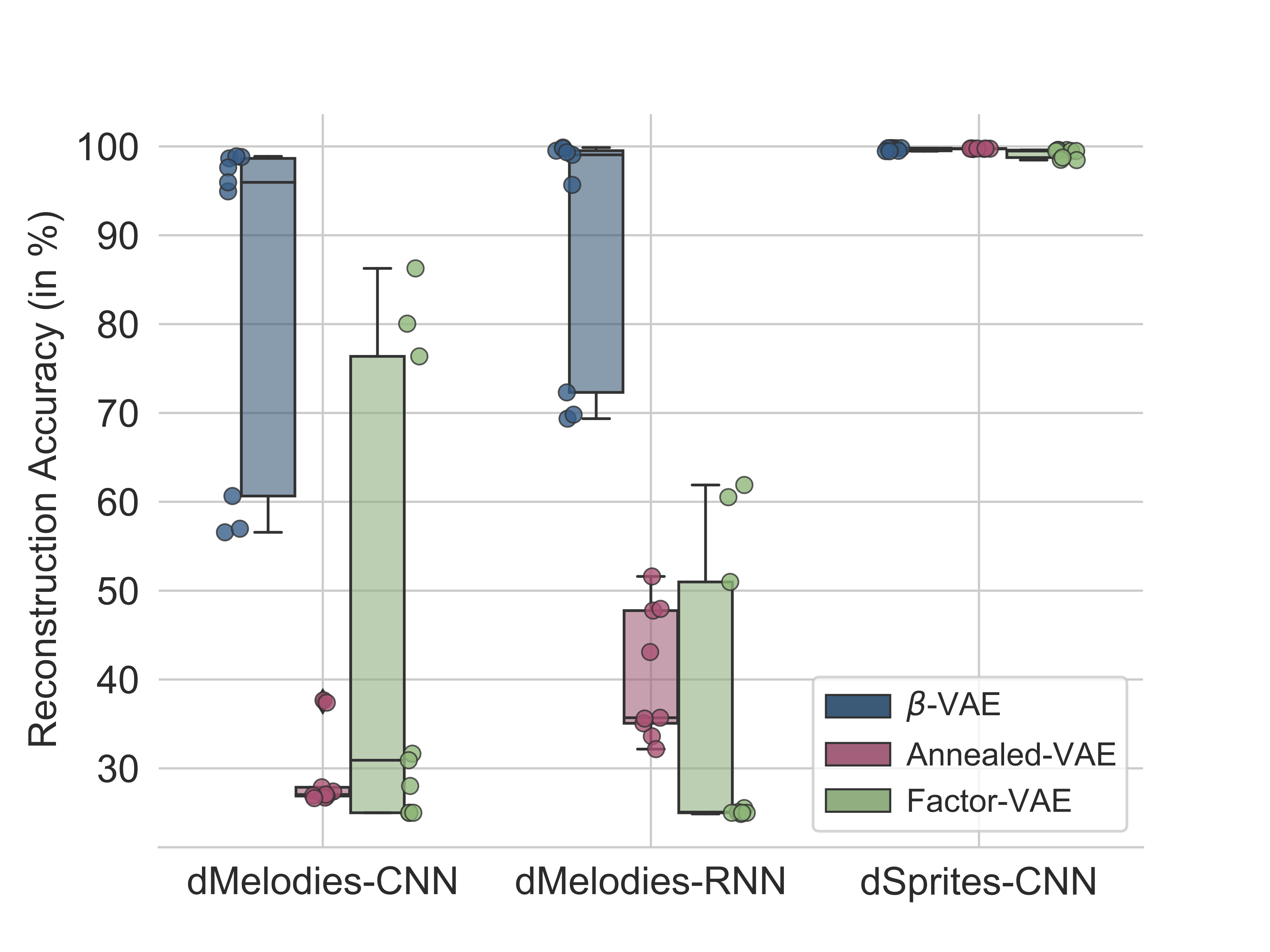
Thus, methods which work well for image-based datasets do not extend directly to the music domain. This showcases the need for further research on domain-invariant algorithms for disentanglement learning. We hope this dataset is a step forward in that direction.
Resources
The dataset is available on our Github repository. The code for reproducing our benchmarking experiments is available here. Please see the full paper (to appear in ISMIR ’20) for a more in-depth discussion on the dataset design process and additional results from the benchmarking experiments.

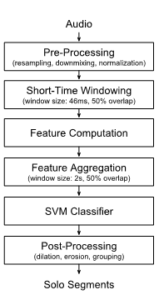 The widespread use of effect pedal boards and amps results in a plethora of different electric guitar “sounds,” possibly almost as large as the number of solos themselves. Hence, finding audio descriptors capable of discriminating a solo from a non-solo part is NOT a trivial task. To gauge how difficult this actually is, we implemented a Support Vector Machine (SVM) based supervised classification system (see the overall block diagram in Fig. 2).
The widespread use of effect pedal boards and amps results in a plethora of different electric guitar “sounds,” possibly almost as large as the number of solos themselves. Hence, finding audio descriptors capable of discriminating a solo from a non-solo part is NOT a trivial task. To gauge how difficult this actually is, we implemented a Support Vector Machine (SVM) based supervised classification system (see the overall block diagram in Fig. 2).