by Chih-Wei Wu
Automatic Drum Transcription (ADT) is an on-going research topic that concerns the extraction of drum events from music signals. After roughly three decades of research on this topic, many methods and several datasets have been proposed to address this problem. However, similar to many other Music Information Retrieval (MIR) research topics, the availability of realistic and carefully curated datasets is one of the bottlenecks for advancing the performance of ADT systems.
In our previous blog post, we briefly discussed this challenge in the context of ADT. With a standard annotated dataset (i.e., ENST drums) and a small collection of unlabeled data, we demonstrated the possibility of harnessing unlabeled music data for improvements in the context of ADT.
In this paper, we explore this idea further in the following directions:
- Identify the major types of ADT systems and investigate generic methods for integrating unlabeled data into these systems accordingly
- Train the systems using a large scale unlabeled music dataset
- Evaluate all systems using multiple labeled datasets currently available
The intention is to validate the idea of using unlabeled data for ADT in a large scale. To achieve this goal, we present two approaches.
Method
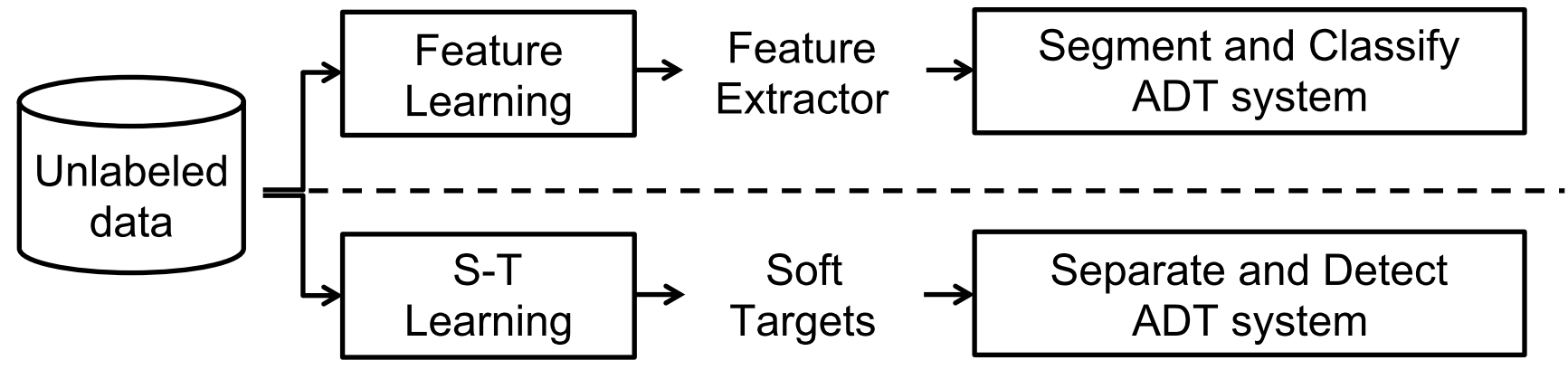
To show that the benefit of using unlabeled data can be generalized to most ADT systems, the first thing is to identify the most popular ADT approaches. To this end, we reviewed existing ADT systems (for more information, please refer to this recent publication), and we found that the two most popular approaches can be categorized as Segment-and-classify ( classification-based) and Separate-and-detect (activation-based).
Based on these two types of approaches, two learning paradigms for incorporating unlabeled data are evaluated. These are
-
- Feature Learning and
- Student Teacher Learning.
As shown in the figure below, both paradigms may extract information from unlabeled data and transfer them to ADT systems through different mechanisms; the feature learning paradigm learns a feature extractor that computes distinctive features from audio signals, whereas the student teacher learning paradigm focuses on generating “pseudo ground truth” (i.e., soft targets) using teacher models and passing them onto student models. Different variants of both paradigms are evaluated.
Results 1: we need more labeled data
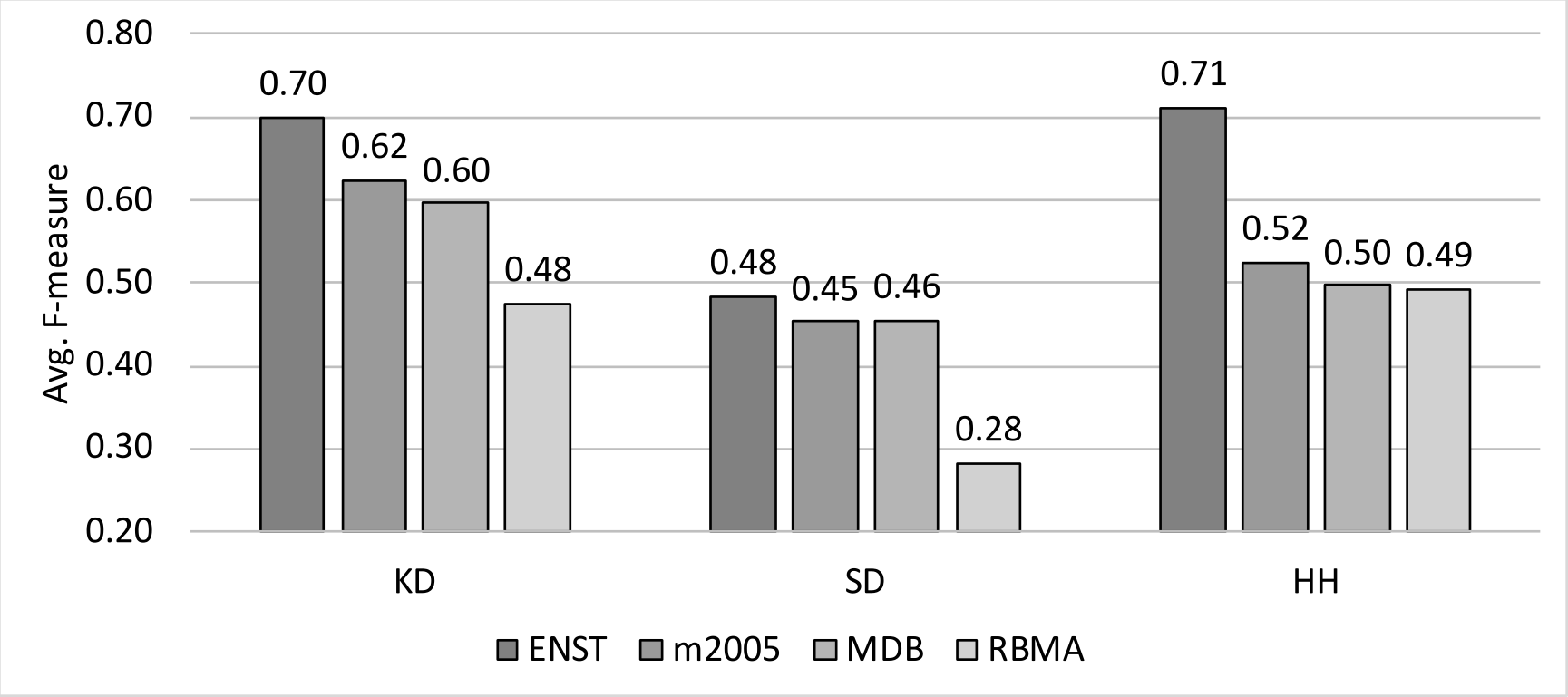
In the first part of the experiment results, the averaged performance across all evaluated systems for each labeled dataset (e.g, ENST drums, MIREX 2005, MDB drums, RBMA) is presented. As shown in the following figure, for each individual drum instrument such as Kick Drum (KD), Snare Drum (SD), and HiHat (HH), the averaged performances differ from dataset to dataset. This result not only shows the relative difficulties of these datasets, but also implies the danger of relying on solely one dataset (which is exactly the case in many prior ADT studies). This result highlights the need for more diverse labeled datasets!
Results 2: unlabeled data is useful
In the second part of the experiment results, different systems for each learning paradigm are compared under the controlled conditions (e.g., training methods, the number of unlabeled examples used, etc.). For feature learning paradigm, as shown in the following table, both evaluated systems outperformed baseline systems on SD for the averaged F-Measure. This improvement was confirmed through a statistical check. This result suggests Segment-and-classify ADT systems can successfully benefit from unlabeled data through feature learning.
| Role | System | HH | BD | SD |
| Baseline | MFCC | 0.61 | 0.62 | 0.40 |
| Baseline | CONV-RANDOM | 0.61 | 0.54 | 0.39 |
| Evaluated | CONV-AE | 0.61 | 0.62 | 0.42 |
| Evaluated | CONV-DAE | 0.61 | 0.61 | 0.42 |
For student-teacher learning paradigm, encouraging results can also be found (this time on HH). In the following table, it is shown that all student models performed better on HH compared to both teacher models. This result indicates the possibility of obtaining students that are better than teachers with the help of unlabeled data. Additionally, this result confirms the finding in our previous paper in a larger scale.
| Role | System | HH | BD | SD |
| Teacher | PFNMF (SMT) | 0.47 | 0.61 | 0.45 |
| Teacher | PFNMF (200D) | 0.47 | 0.67 | 0.40 |
| Student | FC-200 | 0.56 | 0.57 | 0.44 |
| Student | FC-ALL | 0.53 | 0.59 | 0.42 |
| Student | FC-ALL (ALT | 0.55 | 0.58 | 0.44 |
Conclusion
According to the results, both learning paradigms can potential improve the ADT performances with the addition of unlabeled data. However, each paradigm seems to benefit different instruments. In other words, it is not easy to conclude which paradigm is “the way to go” when it comes to harnessing unlabeled resources. To simply put it, unlabeled data certainly has potential in improving ADT systems, and further investigation is worthwhile.
If you are interested in learning more details about this work, please refer to our paper. The code is available on github.