Over the course of the evolution of rock, electric guitar solos have developed into an important feature of any rock song. Their popularity among rock music fans is reflected by lists found online such as here and here. The ability to automatically detect guitar solos could, for example, be used by music browsing and streaming services (like Apple Music and Spotify) to create targeted previews of rock songs. Such an algorithm would also be useful as a pre-processing step for other tasks such as guitar playing style analysis.
What is a Solo?
Even though most listeners can easily identify the location of a guitar solo within a song, it is not a trivial problem for a machine. Looking at it from an audio signal perspective, solos can be very similar to some of the other techniques such as riffs or licks.
Therefore, we define a guitar solo as having the following characteristics:
The guitar is in the foreground compared to other instruments
The guitar plays improvised melodic phrases which don’t repeat over measures (differentiate from a riff)
The section is larger than a few measures (differentiate from a lick)
What about Data?
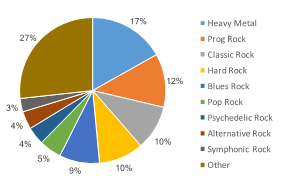
In the absence of any annotated dataset of guitar solos, we decided to create a pilot dataset containing 60 full-length rock songs and annotated the location of the guitar solos within the song. Some of the songs contained in the dataset include classics like “Stairway to Heaven,” “Alive,” and “Hotel California.” The sub-genre distribution of the dataset is shown in Fig. 1.
What Descriptors can be used to discriminate solos?
The widespread use of effect pedal boards and amps results in a plethora of different electric guitar “sounds,” possibly almost as large as the number of solos themselves. Hence, finding audio descriptors capable of discriminating a solo from a non-solo part is NOT a trivial task. To gauge how difficult this actually is, we implemented a Support Vector Machine (SVM) based supervised classification system (see the overall block diagram in Fig. 2).
In addition to the more ubiquitous spectral and temporal audio descriptors (such as Spectral Centroid, Spectral Flux, Mel-Frequency Cepstral Coefficients etc.), we examine two specific class of descriptors which intuitively should have better capacity to differentiate solo segments from non-solo segments.
Descriptors from Fundamental Pitch estimation: A guitar solo is primarily a melodic improvisation and hence, can be expected to have a distinctive fundamental frequency component which would be different from that of another instrument (say a bass guitar). In addition, during a solo the guitar will have a stronger presence in the audio mix which can be measured using the strength of the fundamental frequency component.
Descriptors from Structural Segmentation: A guitar solo generally doesn’t repeat in a song and hence, would not occur in repeated segments of a song (e.g., chorus, song). This allows to leverage existing structural segmentation algorithms in a novel way. A measure of the number of times a segment has been repeated in a song and the normalized length of the segment can serve as useful inputs to the classifier.
By using these features and post-processing to group the identified solo segments together, we obtain a detection accuracy of nearly 78%.
The main purpose of this study was to provide a framework against which more sophisticated solo detection algorithms can be examined. We use relatively simple features to perform a rather complicated task. The performance of features based on structural segmentation is encouraging and warrants further research into developing better features. For interested readers, the full paper as presented at the 2017 AES Conference on Semantic Audio can be found here.
Building a computer system that “listens” and “understands” music is the goal of many researchers working in the field of Music Information Retrieval (MIR). To achieve this objective, identifying effective ways of translating human domain knowledge into computer language is the key. Machine learning (ML) promises to provide methods to fulfill this goal. In short, ML algorithms are capable of making decisions (or predictions) in a way that is similar to human experts; this is achievable by browsing and observing patterns within so called “training data.” When large amounts of data are available (e.g., images and text), modern ML systems can perform comparably or even outperform human experts in tasks such as object recognition in images.
Similarly, to train a successful ML model for MIR tasks, (openly available) data also plays an essential role. Useful training data usually includes both the raw data (e.g., audio files, video files) and annotations that describe the answer for a certain task (such as the music genre, the tempo of the music). With a reasonable amount of data and correct ground truth labels, the ML models may build a function that maps the raw data to their corresponding answers.
One of the first questions new researchers ask is: “How much data is needed to build a good model?” The short answer to the first question is the more the better. This answer may be a little unsatisfying, but it is often true for ML algorithms (especially the increasingly popular deep neural networks!). The human annotation of data, however, is labor-intensive and does not scale well. This situation gets worse when the target task requires highly skilled annotators and crowdsourcing is not an option. Automatic Drum Transcription (ADT), a process that extracts the drum events from the audio signals, is a good example of such skill demanding task. To date, most of the existing ADT datasets are either too small or too simple (synthetic).
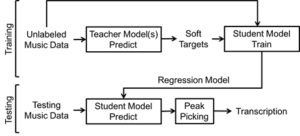
To find a potential solution for this problem, we try to explore the possibility of having ML systems learn from the data without labels (as shown in Fig. 1).
The concept of learning from unlabeled data
Unlabeled data has the following advantages: 1) it is easily available compared to labeled data, 2) it is diverse, and 3) it is realistic.
We explore a fascinating way of using unlabeled data referred to as the “student-teacher” learning paradigm. In a way, it uses “machines to teach machines.” As researchers have been working on systems for drum transcription before, these existing systems can be utilized as teachers. Multiple teachers “transfer” their knowledge to the student and the unlabeled data is used as the medium to carry the knowledge of the teachers. The teachers make their predictions on the unlabeled data and the student will try to mimic the teachers’ predictions and become better and better at certain task. Of course, the teachers might be wrong, but the assumption is that multiple teachers and a large amount of data will compensate for this.
System flowchart
Figure 2 shows the presented system consisting of a training phase and a testing phase. During the training phase, all teacher models will be used to generate their predictions on the unlabeled data. These predictions will become “soft targets” or pseudo ground truth. Next, the student model is trained on the same unlabeled data with the soft targets. In the testing phase, the trained student model will be tested against an existing labeled dataset for evaluation.
The exciting (preliminary) result of this research is that the student model is actually able to outperform the teachers! Through our evaluation, we show that it is possible to get a student model that outperforms the teacher models on certain drum instruments for ADT task. This finding is encouraging and shows the potential benefits we can get from working with unlabeled data.
For more information, please refer to our full paper. The unlabeled dataset can be found on github.
Data availability is the key to the success of many machine learning based Music Information Retrieval (MIR) systems. While there are different potential solutions to deal with insufficient data (for instance., semi-supervised learning, data augmentation, unsupervised learning, self-taught learning), the most direct way of tackling this problem is to create more annotated datasets.
Automatic Drum Transcription (ADT) is, similar to most of the MIR tasks, in need of more realistic and diverse datasets. However, the creation process of such datasets is usually difficult for the following reasons: 1) the synchronization between the drum strokes the onset times has to be exact. In previous work, this was done by installing triggers on the drum sets. However, the installation and the recording process also limits the size of the dataset. Another work around solution is to synthesize drum tracks with user defined onset time and drum samples; this will result in drum tracks with perfect ground truth, but the resulting music might be unrealistic and unrepresentative of the real-world music. 2) the variety of the drum sounds has to be high enough to cover a wide range from electronic to acoustic drum sounds. Most of the previous work only uses a small subset of drum sounds (e.g., certain drum machines or a few drum kits), which is not ideal in this regard. 3) the playing techniques can be hard to differentiate, especially on instruments such as snare drum. A majority of existing datasets only contain the annotations of the basic strikes for simplicity.
We try to address the above mentioned difficulties by introducing a new ADT dataset with a semi-automatic creation process.
Why MDB?
The goal of this project is to create a new dataset with minimum effort from the human annotators. In order to achieve this goal, a robust onset detection algorithm to locate the drum events is important. To ensure the robustness of the onset detector, we want the input signal to be as clean as possible. However, we also want to have a signal to be as realistic as possible (i.e., polyphonic mixtures of both melodic and percussive instruments). With these considerations in mind, we decided to avoid collecting a new dataset from scratch but rather work on the existing dataset with desirable properties.
As a result, the MusicDelta subset in the MedleyDB dataset is chosen for its:
Multitrack format. This can potentially increase the robustness of onset detector and facilitate the semi-automatic annotation process. In addition, the multitrack files can be mixed in any arbitrary combination, providing more possibilities for experimentation.
Real-world recordings. This means the recordings are more realistic and closer to the real use cases. Also, the diversity in terms of music genres offers a more representative sample pool.
Dataset creation
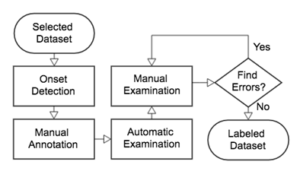
The processing flow of the creation of MDB Drum is shown in Fig. 1. First, the songs in the selected dataset are processed with an onset detector. This provides a consistent estimation of the onset locations. Next, the onsets are labeled with their corresponding instrument names (i.e., Hi-hat, Snare Drum, Kick Drum). This step inevitably requires manual annotation from the human experts. Following the manual annotation, a set of automatic checks were implemented to examine the annotations for common errors (e.g., typos, duplicates). Finally, the human experts went through an iterative process of cross-checking their annotations prior to the release of the dataset.
Flowchart of the dataset creation process
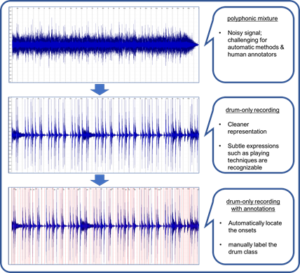
An dataset example is shown in Fig. 2. The original polyphonic mixture (top) appears noisy, and it is difficult to locate the drum events through both listening and visual inspection. The drum-only recording (middle), however, has sharp attacks and short decays in the waveform, providing a cleaner representation for the onset detector. Finally, the detected onsets (bottom), as marked in red, are relatively accurate, which greatly simplifies the process of manual annotation.
One example of the semi-automatic annotation process
Dataset
The resulting dataset contains 23 tracks of real-world music with a diverse distribution of music genres (e.g., rock, disco, grunge, punk, reggae, jazz, funk, latin, country, britpop, to name just a few). The average duration of the tracks is around 54s, and the number of annotated instrument classes is 6 (only major classes) or 21 (with playing techniques). The users may choose to mix the multitracks in any combination (e.g., guitar + drum, bass + drum) due to the multitrack format of the original MedleyDB dataset.
Learning a musical instrument is difficult. It needs regular practice, expert advice, and supervision. Even today, musical training is largely driven by interaction between student and a human teacher plus individual practice session at home.
Can technology improve this process and the learning experience? Can an algorithm perform an assessment of a student music performance? If yes, we are one step closer to a truly musically intelligent music tutoring system that will support students learn their instrument of choice by providing feedback on aspects like rhythmic correctness, note accuracy, etc. An automatic assessment is not only useful to students for their practice sessions but could also help band directors in the auditioning and (pre-)selection process. While there are a few commercial products for practicing instruments, the assessment in these products is usually either trivial or opaque to the user.
The realization of a musically intelligent system for music performance assessment requires knowledge from multiple disciplines such as digital signal processing, machine learning, audio content analysis, musicology, and music psychology. With recent advances in Music Information Retrieval (MIR), noticeable progress has been made in related research topics.
Despite these efforts, identifying a reliable and effective method for assessing music performances remains an unsolved problem. In our study, we explore the effectiveness of various objective descriptors by comparing three sets of features extracted from the audio recording of a music performance, (i) a baseline set with common low-level features (often used but hardly meaningful for this task), (ii) a score-independent set with designed performance features (custom-designed descriptors such as pitch deviation etc., but without knowledge of the musical score), and (iii) a score-based set with designed performance features (taking advantage of the known musical score). The goal is to identify a set of meaningful objective descriptors for the general assessment of student music performances. The data we used covers Alto Saxophone recordings of three years of student auditions (Florida state auditions) rated by experts in the assessment categories of musicality, note accuracy, rhythmic accuracy, and tone quality.
Label: Musicality
E1
E2
E3
E4
Correlation (r)
0.19
0.49
0.56
0.58
Our observations (as seen in Table 1) are that, as expected, the baseline features (E1) are not able to capture any qualitative aspects of the music performance so that the regression model mostly fails to predict the expert assessments . Another expected result is that score-based features (E3) are able represent the data generally better than score-independent features (E2) in all categories. The combination of score-independent and score-based features (E4) show some trend to improve results, but the gain remains small, hinting at redundancies between the feature sets. With values between 0.5 and 0.65 for the correlation between the prediction and the human assessments, there is still a long way to go before computers will be able to reliably assess student music performance, but the results show that an automatic assessment is possible to a certain degree.
It was great to see alumni and current students meet at the International Society for Music Information Retrieval Conference (ISMIR) in Suzhou, China.
Contributions from the group at the conference:
Gururani, S.; Lerch, A., Automatic Sample Detection in Polyphonic Music, Proceedings of the International Society for Music Information Retrieval Conference (ISMIR), ISMIR, Suzhou, 2017.
Xambó, A., Lerch, A., Freeman, J. (2016). Learning to code through MIR. Extended abstracts for the Late-Breaking Demo Session of the 17th International Society for Music Information Retrieval Conference, 2016.
Assessment of Music Performances
Design and evaluation of features for the characterization of (student) music performances and create models to automatically assess these performances, detect errors, and give instantaneous feedback to the performer.
[show_more color=”#eeb211″]Resources
Source repository: github Publications:
– Wu, C.-W.; Gururani, S.; Laguna, C.; Pati, A.; Vidwans, A.; Lerch, A., Towards the Objective Assessment of Music Performances, Proceedings of the International Conference on Music Perception and Cognition (ICMPC), San Francisco, 2016 Contributors (current)
Siddharth Kumar Gururani, Chris Laguna, Ashis Pati, Amruta Jayant Vidwans, Chih-Wei Wu Contributors (past)
Cian O’Brien, Yujia Yan, Ying Zhan
[/show_more]
Automatic Drum Transcription (PhD Project)
Automatic drum transcription in polyphonic mixtures of music using a signal-adaptive NMF-based method.
Audio Quality Enhancement (MS Project)
Web application to improve audio quality of low quality recordings (especially for low quality mobile phone recordings). Processing steps include detecting and correcting clipping (distortion), removing noise, normalization of loudness, and equalization. The REPAIR Web App allows users to upload low-quality audio and download the improved audio.
Automatic Practice Logging (Semester Project)
Automatic identification of continuous recordings of musicians practicing their repertoire. The goal is a detailed description of what and where they practiced, which can be used by students and instructors to communicate about the countless hours spent practicing.
[show_more color=”#eeb211″]
Resources Publications:
– Winters, R. M.; Gururani, S.; Lerch, A., Automatic Practice Logging: Introduction, Dataset & Preliminary Study, Proceedings of the International Conference on Music Information Retrieval (ISMIR), New York, 2016
Source repository: github Contributors
R. Michael Winters, Siddharth Kumar Gururani
[/show_more]
Machine Listening Module (MS Project)
Machine listening provides a set of data with which music can be synthesized, modified, or sonified. Real time audio feature extraction opens up new worlds for interactive music, improvisation, and generative composition. Promoting the use of machine listening as a compositional tool, this project brings the technique into DIY embedded systems such as the Raspberry Pi, integrating machine listening with analog synthesizers in the eurorack format.
[show_more color=”#eeb211″]
Resources
Source repository: github
Project Report:
– Latina, C., Machine Listening Eurorack Module, MS Project Report, Georgia Institute of Technology, 2016. Contributors
Chris Latina
[/show_more]
Sample detection in Polyphonic Music
Sampling, the usage of snippets or loops from existing songs or libraries in new music productions or mashups, is a common technique in many music genres. The goal of this project is to design an NMF-based algorithm that is able to detect the presence of a sample of audio in a set of tracks. The sample audio may be pitch shifted or time stretched so the algorithm should ideally be robust against such manipulation.
[show_more color=”#eeb211″]
Resources Contributors
Siddarth Kumar
[/show_more]
Web Resources for Audio Content Analysis
Online resources for tasks related to music information retrieval and machine learning, including matlab files, a list of datasets, and exercises.
Application of MIR Techniques to Medical Signals
Based on the physionet.org challenge dataset for reducing false alarms in ECG and blood pressure signals, MIR approaches are investigated for the detection of alarm situations in the intensive care unit. The 5 types of alarms asystole, extreme bradycardia, extreme tachycardia, ventricular tachycardia, and ventricular flutter are detected.
Real-time speaker annotation in conference settings
Generating a transcript of a conference meeting requires not only the transcription of text but also assigning the text to specific speakers. This system is designed to detect an unknown number of speakers and assign text to these speakers in a real-time scenario.
Application for Vocal Training and Assessment using Real-Time Pitch Tracking
A cross-platform application for vocal training and evaluation using monophonic pitch tracking. The system is designed to take real-time voice input using standard microphones available in most mobile devices. The assessment is carried out in reference to reference vocal lessons based on pitch and timing accuracy. Real-time feedback is provided to the user in the form of a pitch contour plotted against the reference pitch to be sung.
Vocopter Singing Game
Vocopter is a mobile game adapted from the classic Copter game. Vocopter allows a playful approach to assess the accuracy of intonation.
Project Riyaaz
Riyaaz is an Urdu word which means devoted practice. The project aims at implementating an app that aids the practice of Indian classical vocal music. It requires the student pass through a curriculum of exercises designed to strengthen their grasp of Swara (tonality, pitch) and Tala (rhythm). The interface provides real-time graphical feedback in order to help improving their skills.
A painting is an expression frozen in time. It is the imagination of the viewer that paints the untold past and the future of the captured moment. This project is an attempt to induce movements in a painting evoked by sounds or music. The idea is to extract various descriptors from music, for example, onsets and tonal content, and map them to a function to process an image and bring it to life as well enhance the music listening experience.
[show_more color=”#eeb211″]
Resources Contributors
Avrosh Kumar
[/show_more]
Automatic Audio-Lyrics Alignment
Automatic alignment of song lyrics to audio recordings at the line level. The alignment makes use of voice activity detection, pitch detection, and the detection of repeating structures.
Genre-specific Key Profiles
Investigation of differences and commonalities of audio pitch class profiles of different musical genres.
[show_more color=”#eeb211″]
Resources
Publication: O’Brien, C.; Lerch, A., Genre-Specific Key Profiles; Proceedings of the International Computer Music Conference (ICMC), Denton, 2015. Contributors
Cian O’Brien
[/show_more]
Supervised Feature Learning via Sparse Coding for Music Information Retrieval
Sparse coding allows to learn features from the dataset in an unsupervised way. It is investigated how added supervised training functionality can improve the descriptiveness of the learned features.
Real-time Onset Detection
Design of an Onset Detection Algorithm suitable for real-time processing and a low latency live input scenario.
[show_more color=”#eeb211″]
<Contributors
Rithesh Kumar
[/show_more]
Predominant Instrument Recognition in Polyphonic Audio
Identification of a single predominant instrument per audio file using pitch features, timbre features and features extracted from short-time harmonics.
[show_more color=”#eeb211″]
Contributors
Chris Laguna
[/show_more]
Time-Domain Multi-Pitch Detection with Sparse Additive Modeling
Frame-level multi-pitch detection in the time domain with locally periodic kernel functions and sparsity constraints.
[show_more color=”#eeb211″]
Contributors
Yujia Yan
[/show_more]
Identification of live music performance via ambient audio content features
Automatic identification of recordings of live performance as opposed to studio recordings.
Metric Learning for Music Discovery with Source and Target Playlists
Playlist generation for music exploration by defining sets of source songs and target songs and deriving a playlist through metric learning and boundary constraints.
Audio Chord Detection Using Deep Learning
Improve audio chord detection by using a Deep Network to extract the tonal features from the audio.
[show_more color=”#eeb211″]
Resources
Publication: Zhou, X.; Lerch, A., Chord Detection Using Deep Learning, in Proceedings of the International Conference on Music Information Retrieval (ISMIR), Malaga, 2015. Contributors Xinquan Zhou
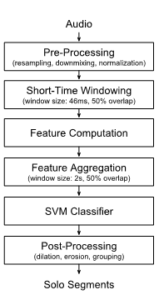 The widespread use of effect pedal boards and amps results in a plethora of different electric guitar “sounds,” possibly almost as large as the number of solos themselves. Hence, finding audio descriptors capable of discriminating a solo from a non-solo part is NOT a trivial task. To gauge how difficult this actually is, we implemented a Support Vector Machine (SVM) based supervised classification system (see the overall block diagram in Fig. 2).
The widespread use of effect pedal boards and amps results in a plethora of different electric guitar “sounds,” possibly almost as large as the number of solos themselves. Hence, finding audio descriptors capable of discriminating a solo from a non-solo part is NOT a trivial task. To gauge how difficult this actually is, we implemented a Support Vector Machine (SVM) based supervised classification system (see the overall block diagram in Fig. 2).